Claude Code의 컨텍스트 윈도우, 왜 30분이면 바닥나는가 - Context Mode의 원리와 효과

Claude Code를 쓰다 보면 난감한 순간이 옵니다. 작업을 시작한 지 30분도 안 됐는데 Claude가 맥락을 잊어버리거나, "auto-compact" 메시지가 뜨면서 이전 대화가 압축되는 겁니다. 방금까지 파일 구조를 완벽하게 파악하고 있던 Claude가 "어떤 파일을 수정하고 계셨나요?"라고 되묻는 경험, Claude Code를 써본 분이라면 한 번쯤 있을 겁니다.
원인은 간단합니다. Claude Code가 MCP 도구를 호출할 때마다 결과물이 통째로 컨텍스트 윈도우에 쌓이거든요. GitHub 이슈 20개를 읽으면 59KB, Playwright로 웹페이지 스냅샷을 찍으면 56KB, 서버 로그 500줄을 분석하면 45KB가 한 번에 들어갑니다. MCP 서버를 여러 개 연결하면 도구 정의만으로도 컨텍스트가 상당 부분 날아갑니다. 200,000 토큰짜리 컨텍스트 윈도우가 작업도 하기 전에 절반 가까이 차버리는 셈입니다. 수치는 뒤에서 자세히 다루겠습니다.
Mert Koseoglu라는 개발자가 이 문제에 주목했습니다. MCP Directory & Hub를 운영하면서 거의 모든 MCP 도구가 원본 데이터를 그대로 컨텍스트에 쌓는 패턴을 발견한 거죠. "도구 출력을 압축하면 어떨까?"라는 질문에서 출발해 Context Mode라는 MCP 서버를 만들었습니다. 결과는 전체 세션의 도구 출력 315KB가 5.4KB로 줄어드는 98% 압축. 세션 지속 시간은 30분에서 3시간으로 늘어났습니다. 이 글에서는 Context Mode의 작동 원리와 실제 효과, 한계를 초보자도 이해할 수 있도록 처음부터 풀어보겠습니다.
컨텍스트 윈도우, Claude Code의 작업 기억
Claude Code를 처음 쓰는 분이라면 컨텍스트 윈도우라는 개념부터 알아야 합니다. 쉽게 말해 Claude가 한 번에 기억할 수 있는 대화의 총량이거든요.
사람으로 치면 작업 중인 책상 위 공간이라고 생각하면 됩니다. 책상이 넓으면 여러 문서를 펼쳐놓고 동시에 참고할 수 있지만, 책상이 좁으면 새 문서를 올릴 때마다 기존 문서를 치워야 합니다. Claude의 컨텍스트 윈도우가 바로 이 책상입니다.
현재 Claude Code는 기본 200,000 토큰의 컨텍스트 윈도우를 사용합니다. 토큰은 대략 한글 한 글자가 1~2 토큰, 영어 한 단어가 1 토큰 정도입니다. 200,000 토큰이면 한글 원고지 500~600매 분량이니 충분해 보입니다. 그런데 실제로 쓰다 보면 이 공간이 놀라울 정도로 빨리 소진됩니다.
이유가 있습니다. Claude Code는 매 턴마다 이전 대화 전체를 다시 읽거든요. 첫 번째 메시지에서 1,000 토큰, 두 번째에서 2,000 토큰을 썼다면, 세 번째 메시지를 처리할 때 Claude는 이전 3,000 토큰 전체를 다시 읽고 나서 새 응답을 생성합니다. 대화가 길어질수록 매 턴의 비용이 선형적으로 늘어나는 구조입니다.
Anthropic 공식 문서에 따르면 베타로 1M(100만) 토큰 컨텍스트도 지원하지만, Claude Opus 4.6과 Sonnet 4.6에서만 가능하고 Usage Tier 4 이상의 조직에만 열려 있습니다. 대부분의 사용자에게는 200K 토큰이 실질적인 한계입니다.
Anthropic 공식 문서에서 설명하는 "context rot"이라는 현상도 있습니다. 컨텍스트에 토큰이 많이 쌓일수록 Claude의 정확도와 재현율이 떨어지는 현상인데요. 200,000 토큰을 꽉 채운 상태에서 Claude의 응답 품질은 여유 있을 때보다 눈에 띄게 나빠집니다. hyperdev 블로그의 분석에 따르면, Claude Code는 컨텍스트의 64~75% 지점에서 자동 압축을 트리거하고, 약 50,000 토큰(25%)을 추론용 "완료 버퍼"로 항상 남겨둡니다. 실제 사용 가능한 공간은 생각보다 훨씬 적은 셈이죠.
MCP, Claude Code가 외부 세계와 소통하는 방법
컨텍스트 윈도우가 왜 빠르게 차는지를 이해하려면 MCP가 무엇인지 알아야 합니다.
MCP는 Model Context Protocol의 약자로, Anthropic이 2024년 11월에 공개한 오픈 표준입니다. 한마디로 AI 모델이 외부 시스템과 소통하는 규격입니다. USB-C가 어떤 기기든 하나의 케이블로 연결할 수 있게 해주듯, MCP는 AI 모델이 GitHub, Slack, 데이터베이스, 파일 시스템 등 어떤 외부 시스템이든 동일한 인터페이스로 접근할 수 있게 합니다.
MCP의 구조는 서버, 클라이언트, 호스트 세 계층입니다. MCP 서버가 외부 데이터나 기능을 노출하고(GitHub MCP 서버라면 이슈 조회, PR 생성 같은 기능), MCP 클라이언트가 AI 앱 측에서 서버와 통신하며, 호스트는 Claude Code나 Claude Desktop 같은 실제 사용자 인터페이스입니다.
Claude Code에서 MCP 도구를 호출하는 과정을 구체적으로 살펴보겠습니다. 사용자가 "이 저장소의 최근 이슈 20개를 분석해줘"라고 요청하면, Claude는 GitHub MCP 서버의 list_issues 도구를 호출합니다. 이 도구가 GitHub API에서 이슈 20개의 데이터를 가져옵니다. 여기까지는 자연스럽습니다. 문제는 그 다음입니다.
가져온 이슈 데이터 전체, 제목, 본문, 라벨, 담당자, 댓글까지 모조리 컨텍스트 윈도우에 들어갑니다. 이슈 20개면 약 59KB, 토큰으로 환산하면 수만 토큰입니다. Claude는 이 데이터를 보고 분석 결과를 생성하는데, 분석이 끝난 후에도 원본 데이터는 컨텍스트에 그대로 남아 있습니다. 다음 대화 턴에서도, 그 다음 턴에서도 계속 공간을 차지합니다.
다음 그림은 기존 방식과 Context Mode 적용 후의 데이터 흐름 차이를 보여줍니다.

기존 방식에서는 MCP 도구의 원본 데이터(59KB)가 컨텍스트 윈도우에 그대로 들어가 공간의 대부분을 차지합니다. Context Mode를 적용하면 샌드박스에서 데이터를 처리한 뒤 핵심 결과(1.1KB)만 컨텍스트에 돌려주므로, 작업에 쓸 수 있는 여유 공간이 크게 늘어납니다.
이게 컨텍스트 소진의 핵심 원인입니다. 도구를 한 번 호출할 때마다 원본 데이터가 컨텍스트에 영구적으로 쌓이거든요. Playwright 스냅샷 한 장에 56KB, 서버 로그 500줄에 45KB, CSV 파일 분석에 85KB. 도구를 대여섯 번만 호출하면 컨텍스트의 상당 부분이 이미 "쓸모를 다한 원본 데이터"로 가득 찹니다.
도구 정의 자체도 컨텍스트를 잡아먹습니다. MCP 서버를 연결하면 해당 서버가 제공하는 모든 도구의 이름, 설명, 매개변수 스키마가 컨텍스트에 올라가거든요. Scott Spence라는 개발자가 블로그에서 직접 측정한 수치가 이 문제의 규모를 잘 보여줍니다. 그가 쓰는 전체 MCP 서버의 도구 정의를 합산하면 81,986 토큰. GitHub, Slack, Sentry, Grafana, Splunk 5개 서버만으로도 약 55,000 토큰입니다. Jira MCP 서버 하나가 약 17,000 토큰, Chrome 관련 MCP 2개가 31,700 토큰입니다. 첫 메시지를 보내기도 전에 200,000 토큰의 약 40%가 사라진 셈입니다.
81개 이상의 도구를 활성화하면 143,000 토큰, 전체 컨텍스트의 72%가 첫 메시지 전에 소비된다는 데이터도 있습니다. 도구 정의, 즉 "이런 도구가 있습니다"라는 설명만으로요. 아직 도구를 한 번도 호출하지 않은 상태입니다. 이 정도면 Claude Code를 실행하자마자 "Context low" 경고가 뜨는 것도 당연합니다.
결국 컨텍스트 소비는 두 방향에서 동시에 일어납니다. 입력 측에서는 도구 정의가, 출력 측에서는 도구 실행 결과가 컨텍스트를 차지합니다. 기존에 이 문제를 해결하려는 시도들은 주로 입력 측에 집중했습니다. 도구 정의를 줄이거나, 필요한 도구만 지연 로딩하는 방식이었죠. Context Mode는 반대 방향, 출력 측을 공략합니다.
기존 컨텍스트 관리 방법과 그 한계
컨텍스트 소진 문제를 알았으니, 현재 Claude Code가 제공하는 관리 기능부터 살펴보겠습니다. Context Mode가 왜 필요한지 이해하려면 기존 방법의 한계를 먼저 알아야 하거든요.
/clear 명령어는 현재 대화를 완전히 초기화합니다. 컨텍스트가 많이 쌓였을 때 새로 시작할 수 있지만, 이전 대화의 모든 맥락이 사라집니다. 복잡한 작업 중간에 /clear를 쓰면 Claude에게 작업 맥락을 처음부터 다시 설명해야 하죠.
auto-compact는 컨텍스트가 일정 수준(64~75%)에 도달하면 자동으로 이전 대화를 압축하는 기능입니다. 요약 방식으로 압축하는데, 이 과정에서 "파일 경로가 뭐였는지", "어떤 변수명을 쓰기로 했는지" 같은 세부 정보가 사라질 수 있습니다.
CLAUDE.md 파일을 프로젝트 루트에 두면 매 세션마다 Claude가 이 파일을 읽어서 프로젝트 맥락을 파악합니다. 컨텍스트가 초기화되어도 기본적인 프로젝트 구조와 규칙은 유지되는데, 이 파일 자체도 컨텍스트를 소비하므로 너무 길게 쓰면 역효과입니다.
MCP 서버 선별도 있습니다. 안 쓰는 MCP 서버는 비활성화하는 거죠. Scott Spence의 측정에 따르면, 도구 20개를 8개로 통합하는 것만으로 8,551 토큰(60%)을 절약할 수 있었습니다. 도구 설명을 간결하게 수정하면 추가 절약도 가능합니다. 87 토큰짜리 도구 설명을 12 토큰으로 줄인 사례도 있습니다.
이런 관리 방법으로도 컨텍스트 문제가 꽤 나아질 수 있습니다. 하지만 핵심 문제는 남아 있습니다. /clear는 맥락을 통째로 날리고, auto-compact는 세부 정보를 잃고, MCP 서버 선별은 도구 정의(입력 측)만 줄일 뿐 도구 출력(출력 측)은 건드리지 못합니다. 도구를 호출할 때마다 원본 데이터가 컨텍스트에 쌓이는 구조 자체는 바뀌지 않는 거죠. Context Mode는 바로 이 출력 측 문제를 공략합니다.
Context Mode의 핵심 아이디어
Context Mode의 발상은 단순합니다. "도구의 실행 결과를 컨텍스트에 넣지 말고, 샌드박스 안에서 처리한 뒤 필요한 결과만 컨텍스트에 돌려주자."
Mert Koseoglu는 Cloudflare가 발표한 Code Mode에서 영감을 받았다고 밝혔습니다. Cloudflare Code Mode는 2,500개의 API 엔드포인트를 2개의 도구(search와 execute)로 축약해서 도구 정의를 117만 토큰에서 약 1,000 토큰으로 99.9% 줄인 프로젝트입니다. 입력 측 압축이죠. Mert는 여기서 "그러면 반대 방향, 도구 출력을 압축하면 어떨까?"라는 질문을 던졌고, 그 답이 Context Mode입니다.
Context Mode는 Claude Code와 MCP 도구 출력 사이에 위치하는 중간 계층입니다. 기존에는 Claude가 도구를 호출하면 결과가 바로 컨텍스트에 들어갔습니다. Context Mode를 설치하면 이 흐름이 바뀝니다. Claude가 Context Mode의 execute 도구를 통해 코드를 실행하면, 그 코드는 격리된 서브프로세스(샌드박스)에서 돌아갑니다. 실행 결과 중 stdout으로 출력된 부분만 컨텍스트에 돌아가고, 나머지 원본 데이터는 샌드박스 안에 남습니다.
왜 이게 통할까요. 대부분의 도구 출력에서 Claude가 실제로 필요한 정보는 전체의 극히 일부입니다. GitHub 이슈 20개의 원본 데이터는 59KB인데, 사용자에게 전달할 분석 결과는 1KB 남짓이면 충분하거든요. 기존에는 59KB 전체가 컨텍스트에 들어갔지만, Context Mode에서는 Claude가 샌드박스 안에서 59KB를 처리하고, 1.1KB의 분석 결과만 컨텍스트에 남깁니다.
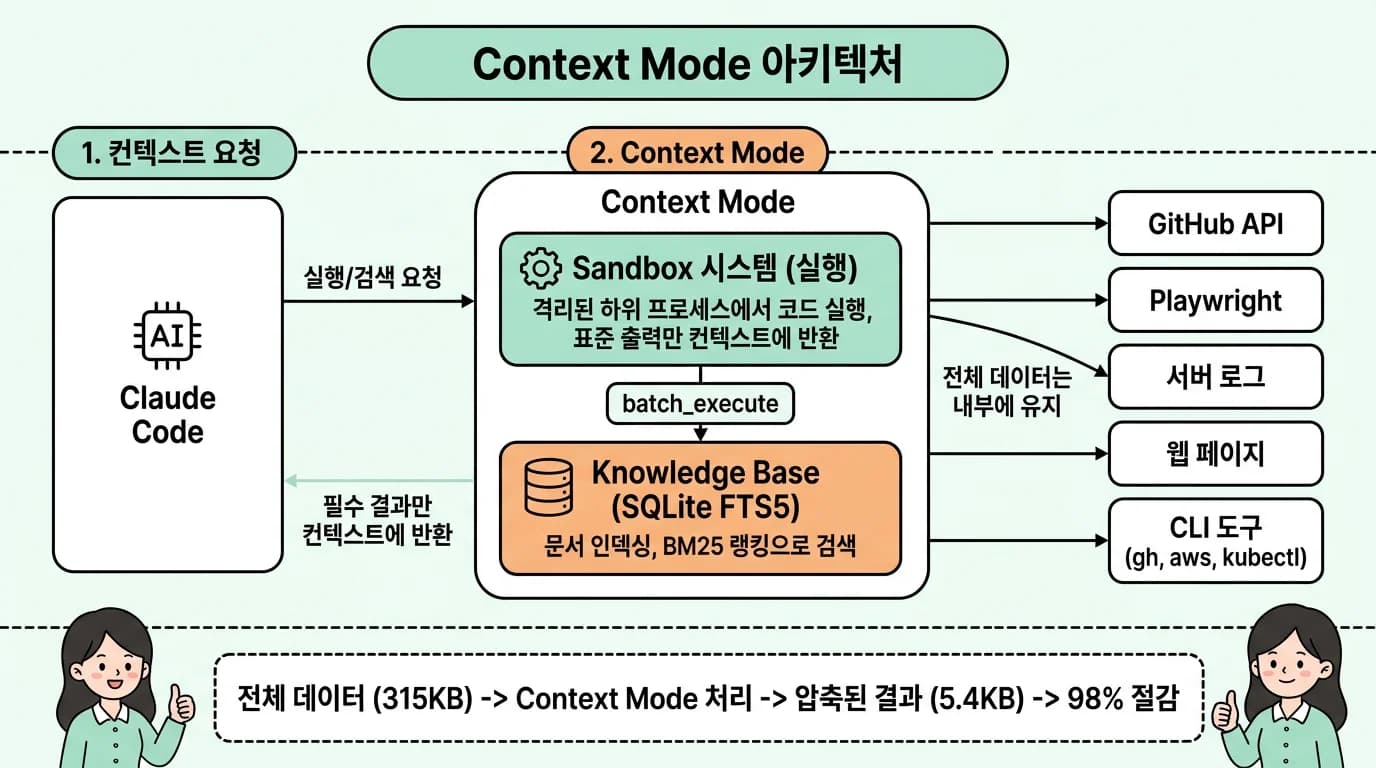
Context Mode는 크게 두 가지 시스템으로 구성됩니다. 하나는 코드를 실행하는 샌드박스 시스템이고, 다른 하나는 대용량 데이터를 검색 가능한 형태로 저장하는 지식베이스 시스템입니다.
다음 그림은 Context Mode의 전체 아키텍처를 보여줍니다.

Claude Code가 요청을 보내면 Context Mode가 중간에서 샌드박스(코드 실행)와 지식베이스(SQLite FTS5 검색)를 통해 외부 도구의 데이터를 처리합니다. 전체 데이터 315KB가 Context Mode를 거치면 5.4KB로 압축되어 컨텍스트에 돌아갑니다.
샌드박스 시스템, 격리된 실행 환경의 작동 원리
샌드박스 시스템은 Context Mode의 핵심 실행 엔진입니다. execute 도구가 호출될 때마다 독립된 서브프로세스를 생성해서 코드를 실행하죠.
구체적인 예를 들겠습니다. Claude가 "이 저장소의 최근 커밋 153개를 분석해줘"라는 요청을 받으면, 기존에는 git log 결과 11.6KB가 통째로 컨텍스트에 들어갔습니다. Context Mode에서는 흐름이 달라집니다.
먼저 Claude는 Context Mode의 execute 도구를 호출하면서 분석용 스크립트를 작성합니다. 예를 들어 "git log를 파싱해서 작성자별 커밋 수, 가장 많이 변경된 파일 Top 10, 주간 커밋 추이를 집계하는 Python 스크립트"를 작성합니다. 이 스크립트는 격리된 서브프로세스에서 실행됩니다. 서브프로세스 안에서 git log의 원본 데이터 11.6KB를 읽고 처리합니다. 최종적으로 stdout에 집계 결과만 출력합니다. stdout으로 출력된 107바이트만 컨텍스트에 돌아갑니다. 11.6KB가 107바이트로 줄어드는 99.1% 압축입니다.
서브프로세스는 매 호출마다 새로 생성되므로 실행 간 상태가 공유되지 않습니다. 한 실행에서 생긴 부작용이 다음 실행에 영향을 주지 않는 구조입니다.
지원하는 런타임은 JavaScript, TypeScript, Python, Shell, Ruby, Go, Rust, PHP, Perl, R, Elixir까지 11개입니다. JavaScript와 TypeScript는 시스템에 Bun이 설치되어 있으면 자동 감지해서 Node.js 대신 Bun으로 실행합니다. Bun은 JavaScript 런타임 중 시작 속도가 가장 빠르기 때문에 빈번한 서브프로세스 생성에서 3~5배 빠른 실행 속도를 기대할 수 있습니다.
인증이 필요한 CLI 도구들도 샌드박스 안에서 작동합니다. gh(GitHub CLI), aws, gcloud, kubectl, docker 같은 도구들이 시스템의 환경 변수를 상속받아 인증 정보를 쓸 수 있는데, 이 인증 정보가 컨텍스트에는 노출되지 않습니다. 기존에는 gh 명령어의 출력이 컨텍스트에 들어가면서 토큰이나 사용자 정보가 노출될 위험이 있었지만, 샌드박스 안에서 처리하면 stdout에 명시적으로 출력한 내용만 컨텍스트에 돌아가거든요.
다만 보안상 주의할 점이 있습니다. 샌드박스가 시스템 환경 변수를 상속받는다는 건, Claude가 작성한 스크립트가 AWS 키, GCP 서비스 계정 토큰, kubectl 컨텍스트 같은 민감 정보에 접근할 수 있다는 뜻이기도 합니다. Claude가 의도치 않게 프로덕션 클러스터를 조작하거나, 잘못된 AWS 리소스를 변경하는 스크립트를 작성할 위험이 있죠. 프로덕션 환경의 인증 정보가 있는 머신에서는 읽기 전용 토큰을 발급하거나, 별도의 샌드박스 프로파일을 설정하는 것이 안전합니다.
batch_execute라는 도구도 있습니다. 여러 개의 실행을 하나의 호출로 묶는 기능인데요. "파일 A를 읽고, 파일 B를 읽고, 두 파일을 비교해줘"라는 요청을 생각해 보겠습니다. 기존에는 세 번의 도구 호출이 필요했고, 각 호출마다 원본 데이터가 컨텍스트에 쌓였습니다. batch_execute를 쓰면 한 번의 호출로 세 작업을 모두 처리하고, 최종 비교 결과만 컨텍스트에 돌려줍니다. 호출 횟수가 줄면 컨텍스트 소비도 줄고, 응답 속도도 빨라지죠.
서브에이전트의 토큰 낭비 문제와도 관련됩니다. dev.to의 한 분석 글에 따르면, Claude Code의 서브프로세스는 시작할 때마다 CLAUDE.md, 플러그인, MCP 도구 설명 등을 재로드합니다. 서브프로세스를 5턴 실행하면 최대 250,000 토큰이 누적될 수 있는데요. batch_execute는 여러 작업을 하나의 서브프로세스에서 처리하므로 이런 반복 로딩 오버헤드를 줄여줍니다.
프로그레시브 검색 스로틀링이라는 기능도 있습니다. 같은 세션에서 search 도구를 반복 호출하면 호출 횟수에 따라 동작이 달라지는데요. 1~3회까지는 정상 검색, 4~8회에서는 결과량을 줄이고, 9회 이상부터는 검색을 차단하고 batch_execute로 리디렉션합니다. Claude가 비효율적인 검색 루프에 빠지는 걸 방지하는 장치죠.
지식베이스 시스템, SQLite FTS5로 대용량 데이터를 다루는 법
샌드박스가 코드 실행을 담당한다면, 지식베이스는 대용량 텍스트 데이터의 저장과 검색을 담당합니다. 웹 페이지 전체 내용, 긴 문서, API 응답 같은 데이터를 컨텍스트에 넣지 않고도 필요할 때 꺼내 쓸 수 있게 해주는 시스템입니다.
지식베이스의 핵심 기술은 SQLite FTS5입니다. 하나씩 풀어보겠습니다.
SQLite는 가장 널리 쓰이는 경량 데이터베이스입니다. 별도 서버 없이 파일 하나로 동작하기 때문에 Python이나 Node.js 같은 런타임에 기본 내장되어 있는 경우가 많습니다. Context Mode가 Pinecone이나 Weaviate 같은 벡터 데이터베이스 대신 SQLite를 선택한 이유가 여기에 있습니다. 추가 설치가 필요 없고, MCP 서버 자체에 내장할 수 있고, 단일 파일이라 세션이 끝나면 깔끔하게 정리되거든요.
FTS5는 Full-Text Search version 5의 약자로, SQLite에 내장된 전문 검색 엔진입니다. 일반적인 SQL의 LIKE '%keyword%' 검색은 테이블의 모든 행을 하나씩 비교하기 때문에 데이터가 많아지면 느려집니다. 시간복잡도로 O(N x M), 데이터 건수(N)와 검색어 길이(M)에 비례하죠. FTS5는 역인덱스를 씁니다. 문서를 저장할 때 각 단어가 어떤 문서의 어떤 위치에 나타나는지를 미리 기록해두는 방식인데, 검색할 때는 이 인덱스만 찾아보면 되므로 O(log n) 수준의 속도가 나옵니다. SQLite 공식 문서에 따르면 1,636MB 크기의 이메일 데이터셋에서 FTS 인덱스(743MB)를 사용한 검색이 밀리초 단위로 응답합니다.
BM25, 검색 결과의 우선순위를 매기는 알고리즘
FTS5가 "어떤 문서에 검색어가 들어있는가"를 찾는다면, BM25는 "찾은 문서들 중 어떤 것이 가장 관련성이 높은가"를 판단합니다.
BM25는 TF-IDF(용어 빈도-역문서 빈도)의 확률적 개선 버전입니다. TF-IDF부터 설명하겠습니다.
TF(Term Frequency, 용어 빈도)는 특정 단어가 한 문서 안에서 얼마나 자주 나타나는지입니다. "React"라는 단어가 문서 A에서 10번, 문서 B에서 2번 나타난다면, TF 기준으로 문서 A가 더 관련성이 높습니다.
IDF(Inverse Document Frequency, 역문서 빈도)는 해당 단어가 전체 문서 모음에서 얼마나 흔한지의 역수입니다. "the"같은 단어는 거의 모든 문서에 나타나므로 IDF가 낮습니다. 반면 "BM25"같은 단어는 소수의 문서에만 나타나므로 IDF가 높습니다. IDF가 높은 단어일수록 검색에서 더 중요하게 취급됩니다.
BM25는 여기에 문서 길이 정규화를 추가합니다. 1,000 단어짜리 문서에서 "React"가 10번 나오는 것과, 100 단어짜리 문서에서 "React"가 10번 나오는 것은 의미가 다릅니다. 짧은 문서에서 같은 횟수로 등장한다면 그 단어의 중요도가 더 높다고 볼 수 있습니다. BM25는 이런 차이를 반영합니다. SQLite FTS5에서 BM25의 매개변수는 k1=1.2, b=0.75로 고정되어 있는데, k1은 용어 빈도의 포화 속도를, b는 문서 길이 정규화의 강도를 조절합니다.
Context Mode에서 BM25의 역할은 간단합니다. 지식베이스에 인덱싱된 수십, 수백 개의 문서 청크 중에서 사용자의 질문과 가장 관련성 높은 청크를 빠르게 찾아주는 겁니다.
Porter Stemming, 단어 변형을 하나로 묶는 기술
Porter stemming은 영어 단어의 어간을 추출하는 알고리즘입니다. "running", "runs", "ran"은 모두 "run"이라는 같은 의미의 변형입니다. 사용자가 "running"으로 검색했을 때 "runs"가 들어있는 문서도 찾아야 검색 품질이 올라갑니다. Porter stemming은 이런 단어 변형을 하나의 어간으로 통일시켜 검색 범위를 넓힙니다.
구체적으로 Porter stemming은 영어 단어의 접미사를 단계적으로 제거합니다. "caresses"는 "caress"로, "ponies"는 "poni"로, "cats"는 "cat"으로 변환합니다. 완벽한 어근 분석은 아니지만(예를 들어 "poni"는 정확한 어근이 아닙니다), 검색 목적에는 충분합니다. 같은 어간으로 변환된 단어들이 하나의 인덱스 항목으로 묶이기 때문입니다.
3계층 퍼지 검색
Context Mode의 지식베이스는 여기서 한 단계 더 나갑니다. BM25 + Porter stemming의 정확 매칭에 더해, 3계층 퍼지 검색 시스템을 갖추고 있습니다.
1계층은 Porter stemming 기반의 어간 매칭으로, 가장 정확하고 빠릅니다. 2계층은 트라이그램 부분 문자열 매칭입니다. 검색어를 3글자 단위로 쪼개서 부분 일치를 찾는 건데, "context"라는 단어를 "con", "ont", "nte", "tex", "ext"로 쪼갠 뒤 이 조각들이 포함된 문서를 찾습니다. 1계층에서 결과가 부족할 때 발동하죠. 3계층은 Levenshtein 거리 기반 오류 정정입니다. 오타나 철자 오류가 있어도 "가장 가까운" 단어를 찾아줍니다. "contxt"로 검색해도 "context"가 나옵니다.
지식베이스의 데이터 흐름
지식베이스에 데이터가 들어가고 검색되는 전체 흐름을 정리하겠습니다.
먼저 인덱싱 단계입니다. index 도구를 사용하면 마크다운 콘텐츠를 제목 기준으로 청킹합니다. 예를 들어 긴 API 문서를 넣으면, H1, H2 등의 제목을 기준으로 의미 있는 단위로 나누어 저장합니다. 코드 블록은 분리하지 않고 해당 섹션에 포함시켜 유지합니다. fetch_and_index 도구를 쓰면 URL에서 HTML을 가져와 마크다운으로 변환한 뒤 같은 방식으로 인덱싱합니다. 원본 HTML이 컨텍스트에 들어가지 않으므로 대용량 웹 페이지도 부담 없이 처리할 수 있습니다.
검색할 때는 search 도구를 씁니다. Claude가 특정 정보가 필요하면 search를 호출하고, FTS5 + BM25가 가장 관련성 높은 청크를 반환합니다. 여기서 중요한 건 반환되는 게 요약이 아니라 정확한 원문 코드 블록이나 텍스트라는 점입니다. 요약 과정에서 정보가 날아가는 게 아니라, 관련 있는 부분만 정확하게 뽑아오는 거죠.
실제 시나리오 몇 가지를 보면 감이 올 겁니다.
Stripe API 문서를 fetch_and_index로 인덱싱했다고 가정합니다. Claude에게 "결제 환불 처리 방법"을 물으면 search 도구가 "refund payment"를 검색합니다. FTS5는 Porter stemming으로 "refund"와 "refunds", "refunded" 등의 변형을 매칭하고, BM25가 가장 관련성 높은 청크를 반환합니다. 돌아오는 건 Refunds API 섹션의 원문 텍스트와 코드 예제입니다. 수백 페이지짜리 API 문서 전체가 아니라 환불 관련 섹션 2~3KB만 컨텍스트에 들어가는 거죠.
Kubernetes 문서도 마찬가지입니다. 문서 전체를 fetch_and_index로 인덱싱한 뒤 Claude가 "Pod 재시작 정책"에 대해 질문받으면, search 도구로 "restart policy pod"를 검색합니다. BM25가 가장 관련성 높은 청크를 반환하고, 돌아오는 건 restartPolicy 섹션의 원문 텍스트와 YAML 예제입니다. 100KB짜리 문서에서 2~3KB만 소비하는 셈이죠.
git log 출력을 index로 인덱싱하면 대규모 프로젝트의 변경 이력 추적에도 쓸 수 있습니다. 커밋 메시지 수천 개를 컨텍스트에 넣는 대신, "authentication refactor" 같은 검색어로 관련 커밋만 뽑아오는 방식입니다.
세 시나리오 모두 원본 데이터 전체를 컨텍스트에 넣지 않고도 필요한 정보에 접근할 수 있다는 공통점이 있습니다. 요약이 아니라 원문 해당 부분을 그대로 반환하기 때문에 코드 예제나 설정 값 같은 정확한 정보가 보존됩니다.
벡터 데이터베이스를 쓰지 않은 이유도 여기서 드러납니다. Pinecone이나 Weaviate 같은 벡터 DB는 의미적 유사성 검색에 강하지만 별도 서버 프로세스가 필요하고 임베딩 모델 의존성이 생깁니다. MCP 서버 하나를 설치하는 데 벡터 DB까지 설정해야 한다면 진입 장벽이 올라가죠. SQLite FTS5는 npm 패키지 안에 내장할 수 있어서 npx 한 줄로 설치가 끝나는 경험을 만들 수 있었습니다.
실제 압축 효과, 숫자로 보는 Context Mode
Context Mode 개발자 Mert Koseoglu가 공개한 측정 데이터를 살펴보겠습니다. 미리 밝힐 점이 있는데요. 아래 수치는 모두 원작자가 특정 워크로드에서 직접 측정한 것이고, 제3자의 독립 검증 데이터는 아직 없습니다. 실제 압축률은 도구 출력의 성격에 따라 크게 달라질 수 있습니다. 단순 데이터 집계(로그, CSV)에서는 99%에 가까운 압축률이 나오지만, 맥락적 분석이 필요한 작업에서는 그보다 낮아집니다. 이 점을 감안하고 보겠습니다.
| 작업 유형 | 원본 크기 | 압축 후 | 감소율 |
|---|---|---|---|
| Playwright 스냅샷 | 56 KB | 299 B | 99.5% |
| GitHub 이슈 20개 | 59 KB | 1.1 KB | 98.1% |
| 액세스 로그 500건 | 45 KB | 155 B | 99.7% |
| CSV 분석 500행 | 85 KB | 222 B | 99.7% |
| Git 로그 153커밋 | 11.6 KB | 107 B | 99.1% |
| 저장소 연구(서브에이전트) | 986 KB | 62 KB | 93.7% |
| 대규모 JSON API | 7.5 MB | 0.9 KB | 99%+ |
| 전체 세션 합계 | 315 KB | 5.4 KB | 98% |
가장 극적인 사례는 Playwright 스냅샷입니다. 웹 페이지의 DOM 스냅샷 56KB가 299바이트로 줄어들었습니다. 99.5% 압축입니다. Playwright로 웹 페이지를 테스트할 때 DOM 구조 전체가 컨텍스트에 들어가면 한 번의 스냅샷으로 약 14,000 토큰이 소비됩니다. Context Mode를 쓰면 Claude가 샌드박스 안에서 DOM을 파싱하고, 필요한 요소의 상태만 stdout으로 출력합니다.
GitHub 이슈 20개는 59KB에서 1.1KB로 줄어들었습니다. 98.1% 압축입니다. 이슈의 제목, 라벨, 상태 같은 핵심 정보만 집계되어 돌아옵니다.
서버 액세스 로그 500건은 45KB에서 155바이트로, CSV 데이터 500행은 85KB에서 222바이트로 압축됩니다. 99.7% 수준입니다. 로그나 데이터 분석에서는 원본 데이터보다 집계 결과가 중요하기 때문에 이런 높은 압축률이 가능합니다.
대규모 JSON API 응답의 경우 7.5MB에서 0.9KB로 줄어듭니다. 99% 이상의 압축률입니다. 마이크로서비스 아키텍처에서 여러 API의 응답을 분석해야 하는 상황을 생각해보면, 이 수치의 의미가 와닿습니다. API 응답 하나가 수 메가바이트인 경우, Context Mode 없이는 한두 번의 API 호출만으로 컨텍스트가 가득 찹니다.
눈여겨볼 부분은 저장소 연구(서브에이전트) 항목입니다. 986KB에서 62KB로, 다른 항목에 비하면 93.7%라는 상대적으로 낮은 압축률이죠. 서브에이전트가 코드베이스를 탐색하면서 생성하는 출력은 단순 집계와 달리 코드 구조에 대한 맥락적 분석이 포함되어 있어 압축이 어렵기 때문입니다. 모든 도구 출력이 같은 비율로 압축되는 건 아닙니다.
전체 세션 기준으로 보면, Context Mode 미적용 시 도구 출력 315KB가 컨텍스트에 쌓이지만, 적용 시 5.4KB만 쌓입니다. 98% 압축입니다.
세션 지속 시간의 변화
세션 지속 시간에 미치는 영향은 더 직관적입니다.
| 지표 | Context Mode 미적용 | Context Mode 적용 |
|---|---|---|
| 세션 지속 시간 | 약 30분 후 성능 저하 | 약 3시간 안정 유지 |
| 45분 후 컨텍스트 잔여 | 60% | 99% |
| 30분 후 소비율 | 40% 소비 | 1% 소비 |
Context Mode 없이 Claude Code를 사용하면 약 30분 후 성능 저하가 시작됩니다. 45분 시점에서 컨텍스트 잔여량이 60%까지 떨어지고, 자동 압축이 발동하면서 이전 맥락이 소실되기 시작합니다. Context Mode를 적용하면 45분 시점에서 컨텍스트 잔여량이 99%입니다. 세션이 약 3시간까지 안정적으로 유지됩니다.
단순히 "오래 쓸 수 있다"는 것 이상의 의미가 있습니다. 컨텍스트에 여유가 있으면 Claude의 추론 품질이 유지됩니다. Context rot이 발생하지 않기 때문입니다. 복잡한 리팩토링 작업 중간에 Claude가 맥락을 잊어버리는 일이 줄고, /clear를 자주 해야 하는 부담도 줄어듭니다.
구체적인 시나리오로 설명하겠습니다. 대규모 코드베이스에서 인증 시스템을 리팩토링한다고 가정합니다. Claude에게 기존 인증 코드를 읽게 하고, 새 구조를 설계하고, 파일 여러 개를 수정하고, 테스트를 돌리는 작업입니다. Context Mode 없이는 코드 읽기 단계에서 이미 상당한 컨텍스트를 소비합니다. 파일 5~6개를 읽고 분석한 시점에서 auto-compact가 발동하면, Claude는 초반에 읽은 파일 내용을 잊어버립니다. 리팩토링 중간에 "이 함수가 어떤 파일에 있었는지" 다시 물어봐야 하는 상황이 생기는 거죠. Context Mode를 쓰면 코드 읽기에서 소비되는 컨텍스트가 대폭 줄어들어, 설계와 수정 단계까지 하나의 세션에서 이어갈 수 있습니다.
설치와 사용법
Context Mode의 설치는 한 줄로 끝납니다.
claude mcp add context-mode -- npx -y context-mode
이 명령어는 Claude Code의 MCP 서버 목록에 context-mode를 추가합니다. npx -y는 npm 패키지를 별도 설치 없이 바로 실행하는 명령어이고, context-mode가 패키지 이름입니다. Node.js가 설치되어 있어야 하며, 18 버전 이상을 권장합니다.
설치 후에는 별도 설정이 필요 없습니다. Context Mode는 PreToolUse 훅으로 도구 출력을 자동 라우팅합니다. 기존 방식 그대로 Claude Code를 쓰면 됩니다. Claude가 알아서 Context Mode의 도구를 활용하거든요. 사용자 입장에서는 "왜 이번 세션은 오래 가지?" 정도의 차이만 느낄 수 있습니다.
Context Mode의 상태를 확인하고 싶다면 슬래시 명령어를 사용할 수 있습니다.
/context-mode:stats # 현재 세션의 압축 통계 확인 /context-mode:doctor # 설치 및 설정 상태 진단 /context-mode:upgrade # 최신 버전으로 업그레이드
Bun이 설치되어 있으면 JavaScript/TypeScript 실행이 3~5배 빨라지므로, 성능을 더 끌어올리고 싶다면 Bun 설치를 권장합니다.
# macOS brew install oven-sh/bun/bun # 또는 공식 스크립트 curl -fsSL https://bun.sh/install | bash
유사 솔루션 비교, 입력 압축과 출력 압축
컨텍스트 소비 문제를 해결하려는 시도가 Context Mode만 있는 건 아닙니다. 크게 세 가지 접근법이 있고, 각각 압축하는 대상이 다릅니다.
Cloudflare Code Mode - 도구 정의 압축의 극단
Cloudflare Code Mode는 Context Mode에 영감을 준 프로젝트인데, 압축 대상이 반대입니다. Code Mode는 도구 정의, 즉 입력 측을 압축합니다.
Cloudflare는 2,500개의 API 엔드포인트를 가지고 있습니다. 이걸 각각 하나의 MCP 도구로 만들면 도구 정의만 117만 토큰인데, 가장 큰 컨텍스트 윈도우보다도 많은 양이죠. Code Mode는 이 2,500개를 단 2개의 도구(search와 execute)로 축약했습니다. AI 에이전트가 먼저 search로 필요한 엔드포인트를 찾고, execute로 호출하는 구조입니다. 117만 토큰이 약 1,000 토큰으로, 99.9% 압축입니다.
Anthropic Tool Search - 공식 지연 로딩
Anthropic이 2026년 1월에 출시한 Tool Search는 도구의 지연 로딩을 제공합니다. 수백, 수천 개의 도구를 등록해도 모든 도구 정의를 한꺼번에 컨텍스트에 넣지 않습니다. 대신 Claude가 필요한 시점에 검색해서 3~5개의 관련 도구만 로드합니다.
Tool Search는 Regex 변형과 BM25 변형 두 가지를 제공합니다. 도구 설정에서 defer_loading: true를 설정하면 해당 도구는 초기 로딩에서 제외됩니다. Anthropic 공식 문서에 따르면 약 55,000 토큰에 달하던 도구 정의가 3~5개 도구 분량으로 줄어들어 85% 이상 감소합니다. 최대 10,000개까지의 도구 카탈로그를 지원합니다.
세 가지 접근법의 비교
셋을 나란히 놓으면 구도가 보입니다.
| 솔루션 | 압축 대상 | 압축률 | 특징 |
|---|---|---|---|
| Cloudflare Code Mode | 도구 정의 (입력) | 99.9% | 2,500개 도구를 2개로 축약 |
| Anthropic Tool Search | 도구 정의 (입력) | 85%+ | 공식 기능, 최대 10,000개 도구 |
| Context Mode | 도구 출력 (출력) | 98% | 오픈소스, 입력 솔루션과 병행 가능 |
Cloudflare Code Mode는 도구 정의(입력)를 99.9% 압축합니다. 2,500개 도구를 2개로 줄이는 접근인데, Cloudflare API에 특화된 솔루션이라 범용으로 쓸 수는 없습니다. 설계 철학을 참고하기에 좋은 사례죠.
Anthropic Tool Search는 도구 정의(입력)를 85% 압축합니다. Anthropic이 직접 만든 공식 기능이라 안정성이 높고, 최대 10,000개 도구를 지원합니다. defer_loading 설정 하나만 추가하면 되므로 도입 비용이 낮습니다.
Context Mode는 도구 출력을 98% 압축합니다. 다른 두 솔루션과 충돌하지 않고 함께 쓸 수 있습니다.
여기서 중요한 건 Context Mode가 입력 측 솔루션과 함께 쓸 수 있다는 점입니다. Tool Search로 도구 정의를 줄이고, Context Mode로 도구 출력을 줄이면 컨텍스트의 양쪽을 동시에 최적화할 수 있습니다. 입력과 출력을 동시에 압축하면 200,000 토큰 중 실제 대화와 추론에 쓸 수 있는 공간이 크게 늘어납니다.
커뮤니티 반응과 한계점
Context Mode는 GitHub에서 1,400개 이상의 스타를 받았습니다. Hacker News에서도 활발한 토론이 이루어졌고, 긱뉴스에서도 꽤 관심을 받았는데요. 두 커뮤니티 모두에서 타당한 우려가 제기되었습니다.
정확도 손실과 환각 위험
가장 많이 나온 우려입니다. 긱뉴스의 한 댓글은 "153개 git 커밋을 107바이트로 압축하면, Claude가 완벽한 추출 스크립트를 작성해야만 데이터를 볼 수 있다"고 지적했습니다. 기존 방식에서는 Claude가 원본 데이터를 직접 보고 판단했는데, Context Mode에서는 Claude가 작성한 스크립트를 통해 간접적으로 봅니다. 스크립트에 버그가 있으면 잘못된 결과가 돌아오고, Claude는 그걸 사실로 받아들여 환각을 일으킬 수 있죠.
타당한 우려입니다. Context Mode의 효과는 "Claude가 올바른 처리 코드를 작성할 수 있다"는 전제에 의존합니다. 단순한 집계나 필터링은 문제가 적지만, 복잡한 데이터 변환이나 다단계 분석에서는 중간 과정의 오류가 전파될 수 있거든요.
반론도 있습니다. Claude가 원본 데이터를 직접 볼 때도 데이터가 너무 많으면 context rot 때문에 오히려 부정확한 분석을 할 수 있습니다. 결국 "원본을 직접 보되 품질이 떨어지는 것"과 "처리된 데이터를 보되 처리 과정의 정확성에 의존하는 것" 사이의 트레이드오프입니다.
과도한 훅 동작
Context Mode의 PreToolUse 훅이 "너무 공격적"이라는 지적도 있었습니다. 모든 curl, wget 호출을 가로채서 fetch_and_index로 리디렉션하는 동작이 때로는 불필요하다는 건데요. 200바이트짜리 간단한 API 응답까지 샌드박스를 거치면 오히려 오버헤드만 늘어납니다.
프롬프트 캐싱 연속성
Claude Code는 프롬프트 캐싱을 씁니다. 이전 대화 내용이 캐시에 있으면 API 호출 비용과 시간이 절약되는데, Context Mode가 도구 출력을 변형하면 캐시 키가 달라져서 캐시 적중률이 떨어질 수 있다는 우려입니다.
벡터 검색 하이브리드 제안
BM25는 키워드 기반 검색이라 의미적 유사성을 잡지 못합니다. "자동차"로 검색하면 "차량"이 들어간 문서를 못 찾죠. 긱뉴스에서는 BM25와 벡터 검색(Model2Vec 등)을 결합한 하이브리드 검색을 제안하는 의견이 있었습니다. RRF(Reciprocal Rank Fusion)로 두 검색 결과를 합성하면 정확도를 높일 수 있다는 건데, 벡터 검색을 추가하면 의존성이 늘어나고 설치가 복잡해집니다. Context Mode가 SQLite FTS5를 선택한 이유가 바로 경량성과 무설치였거든요.
근본적 해결책에 대한 논의
일부 개발자는 Context Mode 같은 외부 솔루션이 아니라 MCP 프로토콜 자체가 개선되어야 한다고 주장합니다. 현재 MCP 도구는 SQL에 비유하면 "SELECT *"와 같습니다. 필요한 필드만 가져오는 게 아니라 모든 데이터를 가져오거든요. 프로토콜 수준에서 "필요한 부분만 가져오기"가 지원되면 외부 압축 계층 없이도 문제가 해결될 수 있습니다.
서브에이전트 분리를 제안하는 의견도 있었습니다. 메인 에이전트의 컨텍스트 대신 별도 서브에이전트에서 도구를 실행하고, 결과 요약만 메인 에이전트에 전달하는 구조죠. Context Mode의 샌드박스가 이 아이디어와 비슷한 접근을 하고 있지만, 프로토콜 수준의 공식 지원과는 차이가 있습니다.
Mert Koseoglu는 긱뉴스 토론에서 이런 피드백에 직접 답변했습니다. 당시 프로젝트는 228개 스타를 받은 초기 단계였는데, "실제 사용 데이터를 통해 개선 방향을 잡고 있으며, 서브에이전트 라우팅이 핵심"이라고 밝혔습니다. 이후 프로젝트는 빠르게 성장해서 현재 1,400개 이상의 스타를 기록하고 있습니다. 커뮤니티 피드백을 반영하면서 발전하고 있다는 점은 긍정적입니다.
마무리
Context Mode를 실제로 설치하고 써보면, 가장 체감되는 변화는 /clear를 덜 하게 된다는 점입니다. 30분마다 컨텍스트가 바닥나서 대화를 끊어야 했던 작업이 한 세션에서 이어집니다.
완벽한 도구는 아닙니다. Claude가 작성하는 처리 스크립트의 정확성에 의존하고, 키워드 기반 검색의 한계가 있고, 모든 도구 출력을 가로채는 방식이 때로는 오버헤드를 만듭니다. 간단한 작업에서는 샌드박스가 오히려 불필요한 복잡성을 추가할 수도 있습니다. 작은 JSON 응답 하나를 처리하는 데 서브프로세스를 만드는 건 배보다 배꼽이 큰 일입니다.
그래도 200,000 토큰이라는 제한된 공간 안에서 더 오래, 더 정확하게 작업하고 싶다면 도구 출력 압축은 실용적인 선택지입니다.
Context Mode가 제기하는 문제의식 자체도 중요합니다. AI 에이전트 시대에 컨텍스트 윈도우는 가장 소중한 자원인데, 현재 MCP 생태계는 이 자원을 허투루 쓰고 있습니다. 도구 하나가 반환하는 데이터 중 실제로 의미 있는 정보는 전체의 1~2%에 불과한 경우가 많은데, 나머지 98%까지 컨텍스트에 넣는 구조거든요. Context Mode는 이 비효율을 외부에서 해결하는 임시 방편이지만, 장기적으로는 MCP 프로토콜 자체가 "필요한 것만 가져오기"를 지원해야 합니다.
현업 개발자에게 들어보니, Claude Code에서 가장 불편한 순간이 "방금까지 완벽하게 이해하고 있던 코드를 갑자기 잊어버리는 것"이라고 합니다. 컨텍스트 윈도우가 그 기억의 한계입니다. Context Mode가 그 한계를 넓히는 방법 중 하나라면, 한 줄의 설치 명령어로 시도해볼 가치는 충분합니다.
참고 자료
- Mert Koseoglu, "Stop Burning Your Context Window", https://mksg.lu/blog/context-mode
- GitHub 저장소: https://github.com/mksglu/claude-context-mode
- Anthropic, "Context Windows", https://platform.claude.com/docs/en/build-with-claude/context-windows
- Anthropic, "Tool Search Tool", https://platform.claude.com/docs/en/agents-and-tools/tool-use/tool-search-tool
- Cloudflare, "Code Mode: give agents an entire API in 1,000 tokens", https://blog.cloudflare.com/code-mode-mcp/
- SQLite FTS5 공식 문서, https://www.sqlite.org/fts5.html
- Anthropic, "Model Context Protocol", https://www.anthropic.com/news/model-context-protocol
- Scott Spence, "Optimising MCP Server Context Usage in Claude Code", https://scottspence.com/posts/optimising-mcp-server-context-usage-in-claude-code
- hyperdev, "How Claude Code Got Better By Protecting Its Context", https://hyperdev.matsuoka.com/p/how-claude-code-got-better-by-protecting
- paddo.dev, "Claude Code의 숨겨진 MCP 플래그", https://paddo.dev/blog/claude-code-hidden-mcp-flag/
- dev.to, "Why Claude Code Subagents Waste 50K Tokens Per Turn", https://dev.to/jungjaehoon/why-claude-code-subagents-waste-50k-tokens-per-turn-and-how-to-fix-it-41ma
- 긱뉴스 토론, https://news.hada.io/topic?id=27108




댓글
댓글을 작성하려면 이 필요합니다.