블로그 태그 저장 시 500 에러가 나길래 추적해봤더니, 만들어둔 유틸을 안 쓰고 있었다

증상: "An unexpected error occurred"
제가 운영하는 커뮤니티(fullstackfamily.com)에서 블로그 글을 쓸 때 태그를 입력할 수 있습니다. spring-boot, java, next.js 같은 것들.
태그를 좀 길게 입력하고 저장을 눌렀더니 500 에러가 떴습니다. 화면에는 "An unexpected error occurred"만 덜렁 나옵니다. 뭘 잘못한 건지 알 수가 없죠. 서버 로그를 까보니 DataTruncation 예외였습니다. MySQL의 VARCHAR(30) 컬럼에 30자를 넘는 문자열이 들어오면서 발생한 거였습니다.
원인 추적: 프론트엔드에서 DB까지 따라가기
흐름을 프론트엔드부터 DB까지 쫓아갔습니다.
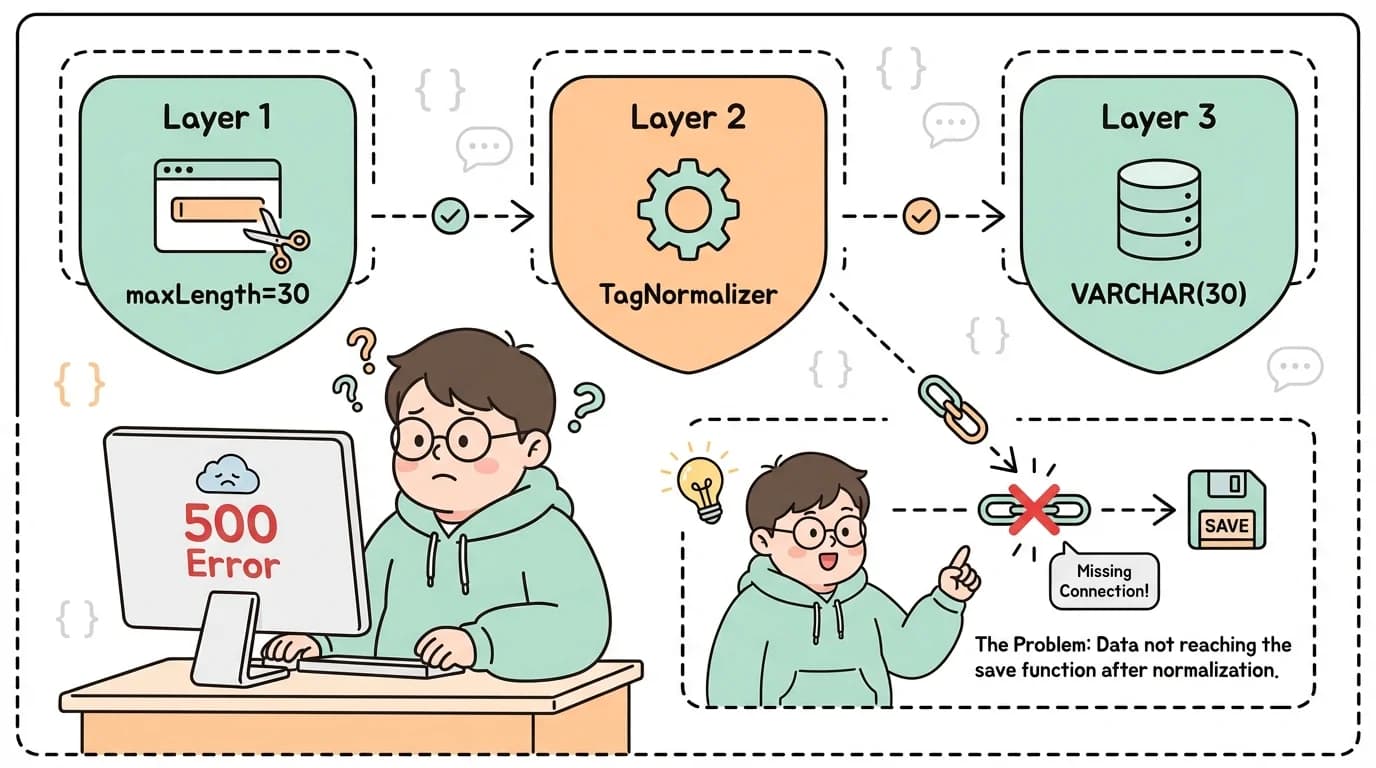
사용자가 50자 태그 입력 → Frontend (TagInput.tsx): 길이 제한 없이 그대로 전송 → Backend DTO: tags 필드 검증 없음 → BlogPostService.savePostTags(): tag.trim().toLowerCase()만 수행 → MySQL unified_post_tag.tag_name: VARCHAR(30) 초과 → DataTruncation 예외 → GlobalExceptionHandler: SQL 예외 핸들러 없음 → 500
입력부터 저장까지 어디에서도 태그 길이를 검사하지 않았습니다. 프론트엔드는 그대로 보내고, 백엔드는 앞뒤 공백만 제거하고, DB에서 결국 터지는 구조였습니다.
이미 있었던 해결책
아이러니한 건, TagNormalizer라는 유틸리티 클래스가 이미 있었다는 겁니다. 태그 검색 시스템을 만들 때 작성해두고, 이후에 해시태그 개인화를 구현하면서 확장까지 했습니다.
하는 일을 보면:
- 허용되지 않는 문자 자동 제거 (정규식
[^a-z0-9가-힣\-.+# ]) - 30자 초과 시 자동 절단
- 공백을 하이픈으로 변환
- 중복 태그 제거
- 게시글당 최대 5개 제한
다 있는데, 정작 BlogPostService.savePostTags()에서는 이걸 안 쓰고 tag.trim().toLowerCase()만 하고 있었습니다.
// 수정 전: TagNormalizer를 안 쓰고 직접 처리 private void savePostTags(UnifiedPost post, List<String> tags) { for (String tag : tags) { String normalized = tag.trim().toLowerCase(); if (!normalized.isEmpty()) { postTagRepository.save(UnifiedPostTag.of(post, normalized)); } } }
만들어놓고 안 쓴 겁니다. savePostTags가 먼저 작성되었고, 나중에 TagNormalizer를 만들면서 기존 코드를 교체하지 않은 거겠죠. 흔한 실수인데, 이런 게 버그가 됩니다.
수정 자체는 간단합니다.
// 수정 후: TagNormalizer.normalizeList() 사용 private void savePostTags(UnifiedPost post, List<String> tags) { List<String> normalizedTags = TagNormalizer.normalizeList(tags); for (String tagName : normalizedTags) { postTagRepository.save(UnifiedPostTag.of(post, tagName)); } }
normalizeList()가 길이 제한, 허용 문자 필터, 중복 제거, 개수 제한을 한 번에 처리합니다.
프론트엔드에도 같은 로직을 넣어야 하는 이유
백엔드만 고치면 되지 않냐고 할 수 있는데, 기능적으로는 맞습니다. 그런데 사용자 경험이 문제입니다.
검증이 없으면 50자짜리 태그를 입력하고 저장 버튼을 누른 뒤에야 에러를 만납니다. 입력 시점에 30자로 잘라주면 그런 일 자체가 없습니다.
TagInput.tsx에 추가한 정규화 함수입니다.
const MAX_TAG_LENGTH = 30 function normalizeTag(raw: string): string { let tag = raw.trim().toLowerCase().replace(/^#+/, '') tag = tag.replace(/[^a-z0-9가-힣\-.+# ]/g, '') tag = tag.replace(/[\s-]+/g, '-') tag = tag.replace(/^-+|-+$/g, '') if (tag.length > MAX_TAG_LENGTH) { tag = tag.substring(0, MAX_TAG_LENGTH) } return tag }
<input maxLength={30}>도 함께 넣어서 입력 자체를 30자로 제한했습니다. 백엔드 TagNormalizer와 같은 규칙이고, 함수 형태만 약간 다릅니다.
VARCHAR(30)과 문자 인코딩 이야기
이 버그를 잡으면서 한 가지 확인해봐야 했던 게, 한글과 영문의 길이 계산이 같은가 하는 점이었습니다. MySQL의 VARCHAR(30)에서 30은 바이트가 아니라 문자 수입니다.
이 프로젝트 DB는 utf8mb4를 씁니다. utf8mb4에서 한글 한 글자는 3바이트를 차지하지만, VARCHAR는 바이트가 아닌 문자 단위로 셉니다. 한글 30자(90바이트)든 영문 30자(30바이트)든 똑같이 저장되고요.
| 입력 | 문자 수 | 바이트 수 | VARCHAR(30) 저장 |
|---|---|---|---|
abcdef...xyz (26자) | 26 | 26 | 가능 |
가나다라마바사아자차카타파하 (14자) | 14 | 42 | 가능 |
spring-boot-application-dev (28자) | 28 | 28 | 가능 |
abcdefghijklmnopqrstuvwxyz12345 (31자) | 31 | 31 | 초과 |
Java의 String.length()도 BMP 문자는 1로 세기 때문에, 한글과 영문은 MySQL과 같은 결과가 나옵니다. substring(0, 30)으로 자르면 MySQL에서도 30자.
이모지는 어떻게 되나
이모지를 태그에 넣으면? TagNormalizer의 정규식 [^a-z0-9가-힣\-.+# ]에서 이모지는 허용 범위 밖이라 정규화 단계에서 제거됩니다.
사실 이모지를 허용했다면 더 귀찮은 문제가 생겼을 겁니다. 이모지 하나가 유니코드에서는 1문자인데, Java String.length()는 서로게이트 쌍(surrogate pair)을 2로 카운트합니다. MySQL은 1로 카운트하고요. Java에서 30자로 잘랐는데 MySQL에서는 15~30자 사이가 되는, 이런 불일치가 나옵니다.
태그처럼 검색에 쓰이는 필드에 이모지를 허용하면 득보다 실이 크다고 판단했습니다.
한글 낱자(ㅁㄴㅇㄹ)가 저장되지 않는 이유
태그에 ㅋㅋㅋ이나 ㅁㄴㅇㄹ을 입력하면 빈 문자열이 되어 저장되지 않습니다. 허용 범위 가-힣의 유니코드 블록을 보면 바로 이해가 됩니다.
유니코드 한글 블록 구조 U+3131 ~ U+314E : 한글 자모 (ㄱ, ㄴ, ㄷ, ..., ㅎ) → TagNormalizer에서 제거됨 U+AC00 ~ U+D7A3 : 한글 음절 (가, 각, 간, ..., 힣) → TagNormalizer에서 허용됨 정규식 [가-힣]은 U+AC00 ~ U+D7A3만 매칭 → ㅁ(U+3131), ㅇ(U+3147) 같은 낱자는 범위 밖
태그는 검색 키워드니까, 의미 없는 낱자를 차단하는 게 맞습니다. ㅋㅋㅋ으로 검색할 사람은 없으니까요.
3계층 방어 설계
수정 후 전체 구조입니다.
[Frontend] [Backend] [DB] TagInput.tsx TagNormalizer MySQL maxLength=30 normalizeList() VARCHAR(30) normalizeTag() 30자 절단 NOT NULL 허용문자 필터 허용문자 필터 UNIQUE KEY │ │ │ ▼ ▼ ▼ 1차 방어 2차 방어 3차 방어 (UX 개선) (비즈니스 로직) (데이터 무결성)
각 계층이 하는 일이 다릅니다.
프론트엔드(1차)는 사용자 경험용입니다. 입력 시점에 길이를 제한하고 특수문자를 걸러주면, 저장 버튼을 누르기 전에 피드백을 받을 수 있습니다.
백엔드(2차)는 비즈니스 규칙을 강제합니다. curl이나 Postman으로 API를 직접 호출하면 프론트엔드 검증은 무의미하거든요. 백엔드에서 TagNormalizer.normalizeList()를 거쳐야 어떤 경로든 같은 정규화가 적용됩니다.
DB(3차)는 최후의 보루입니다. 백엔드에서 정규화를 빼먹더라도(이번에 실제로 그랬듯이), VARCHAR(30) 제약이 잘못된 데이터 저장 자체는 막아줍니다. 다만 DB에만 의존하면 이번처럼 500 에러가 사용자한테 그대로 가는 게 문제입니다.
어느 하나만으로는 부족합니다.
| 계층 조합 | 문제점 |
|---|---|
| 프론트엔드만 | API 직접 호출로 우회 가능 |
| 백엔드만 | 사용자에게 입력 시점 피드백 없음 |
| DB만 | 500 에러가 사용자에게 노출됨 |
| 프론트 + 백엔드 | DB 제약과 불일치 시 데이터 정합성 깨질 수 있음 |
| 3계층 모두 | 각 계층이 역할을 분담, 어느 한 곳이 빠져도 나머지가 방어 |
마무리
TagNormalizer를 만들어놓고 savePostTags()에서 안 썼다. 기술적으로 어려운 문제가 아니라 그냥 빠뜨린 겁니다. 유틸이 있는 줄 몰랐거나, 알았는데 연결을 안 했거나. 어느 쪽이든 결과는 같습니다.
이번 건을 겪으면서 느낀 건, 공통 로직을 유틸로 분리해두는 것까지는 좋은데 실제 호출 경로에서 안 쓰면 의미가 없다는 겁니다. TagNormalizer는 다른 곳에서는 잘 쓰이고 있었고, savePostTags()에서만 빠져 있었습니다. 코드 리뷰에서도 놓치기 쉽습니다.
그리고 입력 검증은 한 곳에서만 하면 안 됩니다. 프론트엔드에서 막고, 백엔드에서 막고, DB에서도 막아야 합니다. 중복 같지만 프론트엔드는 UX, 백엔드는 규칙 강제, DB는 데이터 무결성 — 역할이 다릅니다. 이번에 DB 덕분에 잘못된 데이터가 저장되지는 않았지만, 500 에러로 사용자 경험은 깨졌습니다.
마지막으로, VARCHAR(30)은 바이트가 아니라 문자입니다. utf8mb4를 쓰면 한글이든 영문이든 30문자까지 동일하게 저장됩니다. 다만 이모지는 Java String.length()와 MySQL 사이에 카운팅 차이가 있으니, 검색용 필드에서는 차단하는 게 안전합니다.




댓글
댓글을 작성하려면 이 필요합니다.