GCP 서버리스에서 단일 VM으로: 월 비용 60% 절감한 인프라 마이그레이션

월 30만원짜리 인프라가 10만원이 된 사연
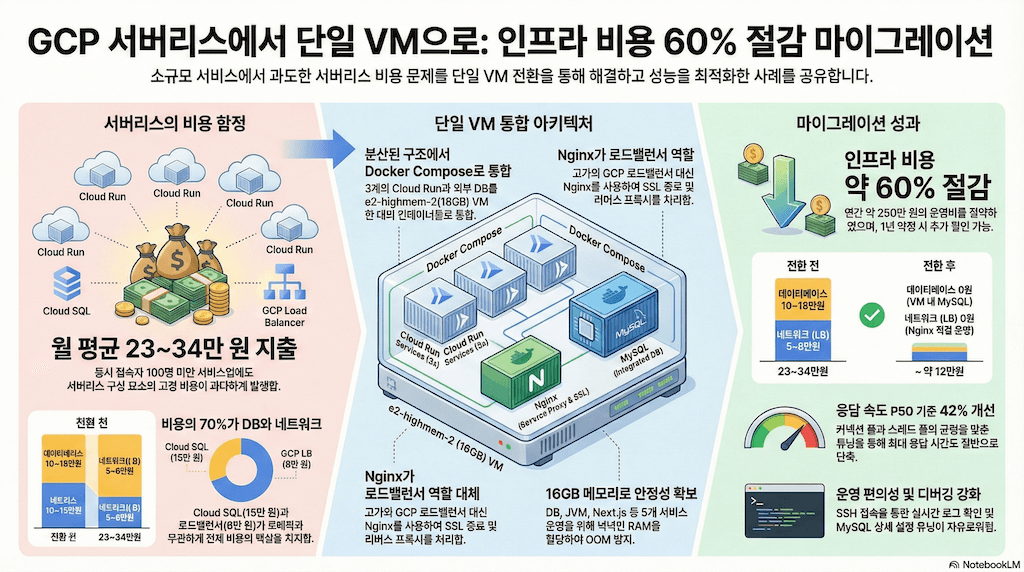
FullStackFamily는 동시 접속자가 100명도 안 되는 소규모 교육 커뮤니티입니다. 그런데 매달 GCP 청구서를 열면 23~34만원이 찍혀 있었습니다.
Cloud Run 3개, Cloud SQL, 로드밸런서, VPC Connector... 서버리스라 "쓴 만큼만 낸다"는 말에 끌려 선택했는데, 현실은 좀 달랐습니다. 트래픽이 적어도 Cloud SQL은 24시간 떠 있어야 하고, 로드밸런서는 고정 비용이 나가고, VPC Connector도 공짜가 아니거든요.
기존 GCP 비용 구조 (월 23~34만원) ┌──────────────────────────────────────────────────┐ │ Cloud SQL (MySQL) 10~15만원 ████████████ │ ← 가장 큰 비중 │ 로드밸런서 + VPC 5~8만원 ██████ │ ← 트래픽과 무관한 고정 비용 │ Cloud Run (Backend) 3~5만원 ████ │ │ Cloud Run (Frontend) 1~2만원 ██ │ │ Cloud Run (Image/기타) 1~3만원 ██ │ │ GCS, DNS, 기타 1~2만원 ██ │ └──────────────────────────────────────────────────┘
Cloud SQL이 절반 가까이를 먹습니다. db-f1-micro로는 불안하니 최소 db-g1-small은 써야 하는데, 그게 만만치 않습니다. 로드밸런서는 트래픽이 0이어도 매달 5만원이 넘고요.
동시 100명도 안 되는 서비스에 이 구조가 맞나? 고민 끝에 GCP Compute Engine VM 한 대로 전부 합치기로 했습니다.
VM을 선택한 이유
다른 선택지도 살펴봤습니다.
┌───────────────────┬──────────┬─────────────┬─────────────────────────┐ │ 선택지 │ 월 비용 │ 서울 지연 │ 탈락 이유 │ ├───────────────────┼──────────┼─────────────┼─────────────────────────┤ │ Railway (싱가포르) │ 6~11만원 │ +100~150ms │ 한국 사용자에겐 체감됨 │ │ Vultr 서울 VPS │ 7만원 │ ~5ms │ 해외 트랜짓 불안 │ │ Oracle Cloud 서울 │ 0원! │ ~5ms │ 인스턴스 쟁탈전, SLA 없음 │ │ GCP VM 서울 │ 10~14만원│ ~5ms │ ← 최종 선택 │ └───────────────────┴──────────┴─────────────┴─────────────────────────┘
Railway가 비용은 제일 나아 보였지만 서버가 싱가포르입니다. 교육 플랫폼에서 100~150ms 추가 지연은 페이지 이동할 때마다 "어... 좀 느린데?" 하는 느낌을 줍니다. 코드 에디터처럼 실시간 인터랙션이 있으면 더 심하고요.
Oracle Cloud 서울은 0원이라 솔직히 혹했는데, Always Free 인스턴스를 만들려면 새벽에 리전을 바꿔가며 찍어야 한다는 후기를 보고 접었습니다. SLA도 없고요.
결국 GCP VM을 골랐습니다. 같은 서울 리전이라 레이턴시가 동일하고, GCS나 VOD 같은 나머지 GCP 서비스와 연동도 자연스럽고, 문제 생기면 DNS만 돌리면 되니까 롤백도 쉽습니다.
전환 전후 아키텍처
Before: 서버리스 분산 구조
사용자 │ ▼ GCP Load Balancer (SSL 종료) ←── 월 5~8만원 ├── www → Cloud Run (Next.js) ── VPC Connector ├── api → Cloud Run (Spring Boot) ── VPC Connector ── Cloud SQL (MySQL) └── img → Cloud Run (Image Service) ↑ 월 10~15만원 │ Cloud SQL Proxy │ 개발자 로컬 (localhost:3307)
After: 단일 VM + Docker Compose
사용자 │ ▼ GCP Compute Engine VM (e2-highmem-2, 16GB, 서울) ←── 월 ~7만원 (1년 약정) │ ├── Nginx (SSL 종료, Let's Encrypt) │ ├── www.fullstackfamily.com → frontend:3000 │ ├── api.fullstackfamily.com → backend:8080 │ └── image.fullstackfamily.com → image-service:3001 │ ├── MySQL 8.0 (Docker) ←── Cloud SQL 비용 0원 │ └── Docker Network (ff-network) └── 5개 컨테이너가 내부 통신 개발자 로컬 ── SSH 터널 (3307→3306) ── VM MySQL
로드밸런서 비용이 사라지고, Cloud SQL 비용이 사라지고, VPC Connector 비용도 사라집니다. 남는 건 VM 한 대 값과 디스크, 그리고 GCS 같은 스토리지 비용뿐입니다.
비용 비교
┌────────────────────┬─────────────┬──────────────────┐ │ 항목 │ Before │ After (1년 약정) │ ├────────────────────┼─────────────┼──────────────────┤ │ 컴퓨팅 │ 5~9만원 │ ~7만원 (VM) │ │ 데이터베이스 │ 10~15만원 │ 0원 (VM 내 MySQL) │ │ 네트워크 (LB) │ 5~8만원 │ 0원 (Nginx 직접) │ │ 디스크 │ 포함 │ ~2만원 (SSD 200G) │ │ GCS + VOD 등 │ ~2만원 │ ~2만원 (유지) │ │ GCP 잔여 서비스 │ 포함 │ ~2만원 │ ├────────────────────┼─────────────┼──────────────────┤ │ 합계 │ 23~34만원 │ ~12만원 │ │ 절감율 │ - │ 약 55~65% │ └────────────────────┴─────────────┴──────────────────┘
최대 22만원 절감. 연간으로 치면 약 250만원입니다. 사이드 프로젝트 치고는 꽤 큰 차이죠.
VM 스펙 선정: 왜 16GB인가
e2-standard-2(8GB)와 e2-highmem-2(16GB) 사이에서 고민했습니다.
서비스별 메모리 할당 계획 ┌─────────────────────┬──────────────┬───────────────────────────┐ │ 서비스 │ 메모리 제한 │ 주요 설정 │ ├─────────────────────┼──────────────┼───────────────────────────┤ │ MySQL 8.0 │ 4GB │ buffer_pool=2G │ │ Spring Boot (JVM) │ 3GB │ -Xmx2g -Xms2g │ │ Next.js │ 1.5GB │ --max-old-space-size=1024 │ │ Image Service │ (제한 없음) │ Sharp + LRU 캐시 │ │ Nginx │ (제한 없음) │ ~50MB │ │ Docker + OS │ - │ ~1.5GB │ ├─────────────────────┼──────────────┼───────────────────────────┤ │ 합계 │ ~10GB │ 여유 ~6GB │ └─────────────────────┴──────────────┴───────────────────────────┘
피크 시 약 10GB를 씁니다. 8GB 머신이면 OOM Killer가 갑자기 MySQL이나 JVM을 죽일 수 있습니다. 한밤중에 그러면 아침까지 서비스가 죽어 있는 거죠. 16GB면 6GB 여유가 있으니 트래픽 급증이나 배치 작업에도 안전합니다.
Docker Compose: 5개 서비스를 하나로
docker-compose.prod.yml ┌─────────────────────────────────────────────────┐ │ nginx (리버스 프록시, SSL 종료) │ │ ├── depends_on: backend (healthy), frontend │ │ └── ports: 80, 443 │ │ │ │ backend (Spring Boot, port 8080) │ │ ├── depends_on: mysql (healthy) │ │ ├── memory: 3GB limit / 2GB reservation │ │ └── healthcheck: /api/health │ │ │ │ frontend (Next.js, port 3000) │ │ ├── depends_on: backend (healthy) │ │ └── memory: 1.5GB limit / 512MB reservation │ │ │ │ mysql (MySQL 8.0, port 3306 internal) │ │ ├── memory: 4GB limit / 3GB reservation │ │ └── healthcheck: mysqladmin ping │ │ │ │ image-service (Sharp, port 3001) │ │ └── GCS bucket 직접 접근 │ └─────────────────────────────────────────────────┘
depends_on에 condition: service_healthy를 걸어두면 MySQL이 완전히 뜬 뒤에 Backend가 시작하고, Backend 헬스체크가 통과해야 Frontend와 Nginx가 올라옵니다. 이 순서가 깨지면 startup이 실패하거든요.
마이그레이션 중 겪은 삽질
처음에 /actuator/health로 헬스체크를 걸었는데 Backend가 계속 unhealthy로 나왔습니다. SecurityConfig에서 /actuator/**에 인증을 걸어놔서 401이 돌아온 거였습니다. public 엔드포인트인 /api/health로 바꾸니 해결.
compose 파일을 수정하고 docker compose restart를 날렸는데 변경이 안 먹힌 적도 있습니다. restart는 compose 파일을 다시 읽지 않습니다. docker compose down && up -d를 해야 합니다. 알고 있는데도 급하면 까먹는 부분이죠.
가장 당황했던 건 이미지 버전 불일치입니다. Artifact Registry의 :latest가 아직 배포 안 된 새 코드를 가리키고 있었습니다. 그 코드에 news_domain_rules라는 테이블을 참조하는 Entity가 있는데 DB에는 그 테이블이 없어서 Schema-validation: missing table 에러가 발생했습니다. Cloud Run에서 실제로 돌고 있던 이미지의 SHA 태그를 확인해서 그걸로 바꿔 해결했습니다.
MySQL 튜닝: Cloud SQL에서 못 건드리던 것들
Cloud SQL은 편한 대신 상세 튜닝이 제한적입니다. VM의 Docker MySQL에서는 production.cnf를 마음대로 쓸 수 있는 게 좋습니다.
[mysqld] # === Memory (VM: 16GB, MySQL target: ~2.5GB) === innodb_buffer_pool_size = 2G # Cloud SQL 기본값보다 넉넉하게 innodb_buffer_pool_instances = 2 # 병렬 접근 개선 innodb_log_file_size = 256M innodb_log_buffer_size = 32M # === SSD I/O 최적화 === innodb_io_capacity = 2000 # SSD라서 200 → 2000 innodb_io_capacity_max = 4000 innodb_flush_method = O_DIRECT # OS 캐시 우회, SSD에서 효과적 # === 커넥션 (Backend HikariCP max 25) === max_connections = 40 # HikariCP 25 + admin/dev 터널 여유 thread_cache_size = 16 # === 안정성과 성능의 균형 === innodb_flush_log_at_trx_commit = 2 # 1초마다 flush (1=매 커밋마다) sync_binlog = 1 # binlog는 엄격하게
여기서 제일 체감이 큰 건 innodb_io_capacity입니다. 기본값 200은 HDD 시절 기준인데, SSD Persistent Disk을 쓰고 있으니 2000으로 올렸습니다. InnoDB가 dirty page를 디스크에 쓰는 속도가 확 빨라집니다.
innodb_flush_log_at_trx_commit = 2는 좀 논쟁이 있는 설정입니다. 1(매 커밋마다 flush)이 제일 안전하지만 쓰기 성능이 절반 가까이 떨어집니다. 2(1초마다 flush)는 최악의 경우 1초치 트랜잭션을 잃을 수 있는데, 교육 커뮤니티에서 1초 유실은 감수할 만하다고 봤습니다.
JVM + HikariCP + Tomcat 튜닝
Backend는 Spring Boot 3.x + JDK 21입니다.
JVM 설정
JAVA_OPTS: > -Xmx2g -Xms2g -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:+UseStringDeduplication -XX:+OptimizeStringConcat -Duser.timezone=Asia/Seoul
| 옵션 | 설명 |
|---|---|
-Xmx2g -Xms2g | 힙을 2GB로 고정. Cloud Run에서는 Xms를 작게 잡았는데, VM에서는 여유가 있으니 GC가 힙 확장할 때마다 생기는 지연을 없앰 |
UseG1GC | 대용량 힙에서 GC 정지 시간을 줄여주는 수집기 |
MaxGCPauseMillis=200 | GC 한 번에 200ms 이내 목표. API 응답에 끼치는 영향 최소화 |
UseStringDeduplication | 중복 문자열 제거. JPA Entity가 같은 태그 이름 등을 수만 번 들고 있으니 효과 있음 |
Tomcat ≈ 커넥션 풀 원칙
처음에는 Tomcat 100스레드, HikariCP 15개로 잡았습니다. Spring Boot 기본값에 가까운 설정이었는데, 부하 테스트를 돌려보니 이 불균형이 눈에 띄었습니다.
튜닝 전: 100개 스레드가 15개 커넥션을 놓고 경쟁 ┌──────────────────────────────────────────────────────────┐ │ Tomcat 100 threads ──→ HikariCP 15 conn ──→ MySQL 50 │ │ ↕ ↑ │ │ Async ~25 threads ──────────┘ │ │ │ │ 문제: 85개 스레드가 커넥션 대기하며 메모리만 차지 │ └──────────────────────────────────────────────────────────┘
Tomcat 스레드가 100개인데 커넥션은 15개뿐이면, 동시에 DB를 쓰려는 요청이 15개를 넘는 순간 나머지 스레드는 커넥션을 받을 때까지 블로킹됩니다. 그 동안 스레드는 아무 일도 못 하면서 메모리만 차지합니다.
여기에 2 vCPU 제약도 있습니다. CPU가 2개인데 스레드 100개를 돌리면 context switching 오버헤드만 늘어납니다. 그리고 Nginx가 이미 IP당 30r/s로 rate limiting을 걸고 있어서, 실제 동시 요청은 피크 때도 15~20개 수준이고요.
그래서 Tomcat 스레드 수 ≈ 커넥션 풀 크기로 맞추되, 비동기 스레드 풀도 고려해서 조정했습니다.
# 튜닝 후 설정 TOMCAT_MAX_THREADS: 30 # 100 → 30 (2 vCPU에 맞게) TOMCAT_MIN_SPARE: 5 # 평상시 대기 스레드 TOMCAT_ACCEPT_COUNT: 50 # 스레드 다 찼을 때 대기 큐 DB_POOL_MAX: 25 # 15 → 25 (Tomcat + async 여유) DB_POOL_MIN_IDLE: 5 # 유지 # MySQL max_connections: 40 # 50 → 40 (HikariCP 25 + admin 여유)
커넥션 풀을 Tomcat과 동일한 30이 아닌 25로 잡은 건, 모든 요청이 DB를 쓰지는 않기 때문입니다. 헬스체크, 캐시 응답, 정적 리소스 같은 건 커넥션이 필요 없으니까요. 대신 비동기 스레드 풀(경험치 계산, 태그 카운트, 알림 등)이 별도로 커넥션을 쓰니 그 여유분을 포함해서 25입니다.
튜닝 후: 스레드와 커넥션이 균형을 이룸 ┌──────────────────────────────────────────────────────────┐ │ Tomcat 30 threads ──→ HikariCP 25 conn ──→ MySQL 40 │ │ ↕ ↑ │ │ Async ~13 threads ──────────┘ │ │ (경험치 8 + 태그 4 + 배너 5 + 알림 ~3) │ │ │ │ 비동기는 @TransactionalEventListener(AFTER_COMMIT) │ │ → Tomcat이 커넥션 반환한 뒤 실행 → 시간차로 재활용 │ └──────────────────────────────────────────────────────────┘
비동기 스레드의 경험치 이벤트(levelExpExecutor)도 max를 16에서 8로 줄였습니다. 2 vCPU에서 16개는 의미 없이 대기만 합니다.
JDBC URL 최적화
jdbc:mysql://mysql:3306/fullstackfamily_core ?cachePrepStmts=true &prepStmtCacheSize=250 &prepStmtCacheSqlLimit=2048 &useServerPrepStmts=true &rewriteBatchedStatements=true
| 옵션 | 효과 |
|---|---|
cachePrepStmts | PreparedStatement 파싱 결과 캐시. JPA가 같은 쿼리를 반복하니 효과 큼 |
prepStmtCacheSize=250 | 캐시할 PS 개수. JPA Entity가 30개 넘으니 250이면 충분 |
useServerPrepStmts | MySQL 서버 측에서 PS를 준비. 파싱 비용 절감 |
rewriteBatchedStatements | 배치 INSERT를 multi-row INSERT로 변환. 태그 카운트 갱신 등에서 효과 |
Nginx: 로드밸런서를 대체하다
GCP 로드밸런서가 하던 일을 Nginx가 전부 맡게 됐습니다. SSL 종료, 리버스 프록시, gzip 압축, rate limiting까지.
# nginx.conf 핵심 설정 worker_processes 2; # vCPU 2개에 맞춤 worker_connections 2048; gzip on; gzip_comp_level 5; # CPU와 압축률의 균형 gzip_min_length 256; # 256B 미만은 압축 안 함 gzip_types text/plain text/css application/json application/javascript image/svg+xml font/woff2; # Rate Limiting limit_req_zone $binary_remote_addr zone=api:10m rate=30r/s;
# fullstackfamily.conf - 서브도메인별 라우팅 server { listen 443 ssl http2; server_name api.fullstackfamily.com; # ... location / { proxy_pass http://backend:8080; proxy_buffering on; limit_req zone=api burst=50 nodelay; } }
proxy_buffering on을 켜두면 Backend 응답을 Nginx가 버퍼에 먼저 받아줍니다. Backend 입장에서는 응답을 보내자마자 커넥션을 놓을 수 있어서 Tomcat 스레드가 빨리 반환되거든요.
rate limiting은 IP당 초당 30건, burst 50(순간 급증 50건까지 허용)으로 잡았습니다. 봇이 초당 수백 건씩 요청을 보내는 걸 막는 용도입니다.
SSL: Let's Encrypt로 무료 전환
GCP 로드밸런서의 managed SSL은 편했지만 공짜가 아니었습니다(로드밸런서 비용에 포함). Let's Encrypt는 무료인 데다 자동 갱신도 됩니다.
SSL 인증서 갱신 자동화 ┌────────────────────────────────────────────────┐ │ cron: 매주 월요일 03:00 │ │ │ │ certbot renew --quiet │ │ → 만료 30일 전이면 자동 갱신 │ │ → 갱신 성공 시 nginx reload │ │ → 갱신 실패 시 이메일 알림 │ └────────────────────────────────────────────────┘
인증서 하나로 fullstackfamily.com, www, api, image 네 도메인을 커버합니다. DNS-01 challenge를 쓰면 와일드카드도 가능하고요.
전환 직후 터진 SSL 문제: TLS 1.3 세션 티켓
DNS 전환을 끝내고 한숨 돌리는데, 게시판에서 이미지 업로드가 안 된다는 걸 발견했습니다. 브라우저 콘솔을 열어보니 이런 에러가 떴습니다.
POST https://api.fullstackfamily.com/api/posts/13727/images net::ERR_SSL_PROTOCOL_ERROR
페이지 조회는 정상인데 API 호출만 실패합니다. www에서 페이지를 로드한 뒤 api로 이미지를 POST하는 순간 SSL 핸드셰이크가 깨지는 거였습니다. Nginx 에러 로그를 열어보니 원인이 보였습니다.
[crit] SSL_do_handshake() failed (SSL: error:0A0000FD:SSL routines::binder does not verify) while SSL handshaking, client: 58.78.106.17, server: 0.0.0.0:443
binder does not verify는 TLS 1.3의 PSK(Pre-Shared Key) 세션 재사용 과정에서 나는 에러입니다. 원인을 정리하면 이렇습니다.
문제 발생 과정 ┌──────────────────────────────────────────────────────────────┐ │ 1. 브라우저가 www.fullstackfamily.com에 TLS 1.3 연결 │ │ → Nginx가 세션을 shared:SSL 캐시에 저장 │ │ │ │ 2. 이미지 업로드 시 api.fullstackfamily.com에 연결 시도 │ │ → Chrome이 캐시된 TLS 세션을 재사용하려고 PSK 전송 │ │ │ │ 3. Nginx가 PSK binder 검증 │ │ → SNI가 www → api로 바뀌었는데 세션은 www 기준 │ │ → binder 불일치 → 핸드셰이크 실패 │ │ → ERR_SSL_PROTOCOL_ERROR │ └──────────────────────────────────────────────────────────────┘
ssl-params.conf에 ssl_session_tickets off로 설정되어 있었습니다. 보안 권장사항을 따른 건데, 이렇게 하면 Nginx가 서버 측 세션 캐시(ssl_session_cache shared:SSL:10m)만 사용합니다. 이 캐시를 www, api, image 세 server 블록이 공유하고 있어서, 서로 다른 서브도메인 간에 세션이 엉키는 겁니다.
Cloud Run + 로드밸런서에서는 GCP가 SSL 종료를 알아서 처리하니까 이런 문제가 없었는데, Nginx로 직접 관리하면서 나타난 거였습니다.
수정은 한 줄입니다.
# ssl-params.conf - ssl_session_tickets off; + ssl_session_tickets on;
세션 티켓을 켜면 TLS 세션 정보가 서버 캐시가 아니라 클라이언트에 암호화된 티켓으로 전달됩니다. 각 서브도메인이 독립적으로 세션을 관리하니까 SNI가 달라도 binder 검증에 걸리지 않습니다.
# VM에서 설정 반영 sudo docker exec ff-nginx nginx -t && sudo docker exec ff-nginx nginx -s reload
reload 후 이미지 업로드가 바로 정상 동작했습니다.
멀티 서브도메인 + 와일드카드 인증서 + Nginx 직접 SSL 종료 조합에서 빠지기 쉬운 함정입니다. 서브도메인이 하나뿐이면 만날 일 없는 문제인데, www, api, image 셋을 한 Nginx에서 돌리니까 생긴 거죠. 로드밸런서가 알아서 해주던 걸 직접 하려면 이런 디테일까지 챙겨야 합니다.
GitHub Actions: Cloud Run → SSH 배포
CI/CD 파이프라인도 바꿨습니다.
Before: git push → GitHub Actions → Docker Build → Push to Artifact Registry → gcloud run deploy After: git push → GitHub Actions → Docker Build → Push to Artifact Registry → SSH로 VM 접속 → docker compose pull → docker compose up -d
Cloud Run에서는 gcloud run deploy 한 줄이면 끝이었는데, VM에서는 SSH로 접속해서 pull하고 재시작해야 합니다.
# backend/.github/workflows/deploy.yml (변경 후) - name: Deploy to VM via SSH uses: appleboy/ssh-action@v1 with: host: ${{ secrets.VM_HOST }} username: ${{ secrets.VM_USER }} key: ${{ secrets.VM_SSH_KEY }} script: | cd /opt/fullstackfamily docker compose pull backend docker compose up -d --no-deps backend
여기서 --no-deps가 중요합니다. 이걸 빼면 Backend를 재시작할 때 의존 관계에 있는 MySQL까지 재시작돼서 잠깐 DB가 끊깁니다. --no-deps를 붙이면 해당 서비스만 교체됩니다.
3개 레포(backend, frontend, image-service) 모두 같은 패턴으로 바꾸고, GitHub Secrets에 VM_HOST, VM_USER, VM_SSH_KEY를 등록했습니다.
배포할 때 10~20초 정도 해당 서비스가 끊깁니다. 이용자가 적은 시간대에 배포하면 실질적으로 문제 없고, Nginx가 502 대신 유지보수 안내 페이지를 보여줍니다.
DNS 전환: 제일 긴장됐던 순간
모든 준비가 끝나면 DNS A 레코드만 바꾸면 됩니다. 간단한 작업인데, 누르는 순간은 좀 떨립니다.
GCP Cloud DNS 레코드 변경 ┌──────────────────────────────┬──────────────────┬──────────────────┐ │ 레코드 │ Before (LB IP) │ After (VM IP) │ ├──────────────────────────────┼──────────────────┼──────────────────┤ │ fullstackfamily.com │ 34.8.179.237 │ 34.64.156.69 │ │ www.fullstackfamily.com │ 34.8.179.237 │ 34.64.156.69 │ │ api.fullstackfamily.com │ 34.8.179.237 │ 34.64.156.69 │ │ image.fullstackfamily.com │ (신규) │ 34.64.156.69 │ └──────────────────────────────┴──────────────────┴──────────────────┘
전환 뒤 기존 GCP 리소스(Cloud Run, Load Balancer, Cloud SQL)는 바로 지우지 않고 동작을 확인한 뒤 순서대로 정리했습니다. 정리 순서가 있거든요. Forwarding Rule → Target Proxy → URL Map → Backend Service → NEG → SSL Cert → Static IP → Cloud Run → Cloud SQL. 의존 관계를 거슬러 올라가며 지워야 합니다.
개발 환경: Cloud SQL Proxy → SSH 터널
개발 환경도 바뀌었습니다. 기존에는 Cloud SQL Proxy로 로컬에서 DB에 접속했는데, 이제 VM 안에 MySQL이 있으니 SSH 터널을 써야 합니다.
# 기존: Cloud SQL Proxy cloud-sql-proxy --port 3307 fullstackfamily:asia-northeast3:ff-mysql # 변경: SSH 터널 ssh -N -f -L 3307:localhost:3306 toto@34.64.156.69
scripts/dev-gcp-start.sh와 dev-gcp-stop.sh를 업데이트해서, 터널 생성/종료 + Backend + Frontend를 한 번에 관리하게 했습니다. 개발자 입장에서는 이전과 동일하게 localhost:3307로 접속하면 됩니다.
운영 자동화: cron 세 줄
VM은 Cloud Run과 달리 직접 관리해야 합니다. 최소한의 cron만 걸어뒀습니다.
┌────────────────────────────────────────────────────┐ │ Cron Jobs │ ├──────────────────┬─────────────────────────────────┤ │ 매 6시간 │ MySQL 전체 백업 → 로컬 보관 │ │ 매주 일요일 4AM │ Docker system prune (미사용 정리) │ │ 매주 월요일 3AM │ certbot renew (SSL 갱신) │ └──────────────────┴─────────────────────────────────┘
MySQL 백업은 mysqldump --single-transaction으로 서비스 중단 없이 돌립니다. binlog도 7일간 보관해서, 필요하면 특정 시점 복구(PITR)도 가능합니다.
Docker는 오래된 이미지와 빌드 캐시가 쌓이니까 주간 정리가 필요합니다. 200GB SSD라 넉넉하긴 한데, 방치하면 몇 달 뒤에 디스크 부족을 만나게 됩니다.
k6 부하 테스트: 진짜 잘 돌아가는지 확인
설정을 다 마친 뒤 Grafana k6로 프로덕션 성능을 측정했습니다. 테스트 시나리오는 세 가지입니다.
vm-api-perf.js 테스트 시나리오 (총 7분) ┌──────────────────────────────────────────────────────────┐ │ 시나리오 1: 단일 사용자 순차 요청 (1 VU, 1분) │ │ → health → home → feed → tags → leaderboard → search │ │ → 서버의 순수 응답 속도 측정 │ │ │ │ 시나리오 2: 동시 사용자 (10~20 VU, 5분) │ │ → 홈 피드 30% / 인기글 20% / 태그 15% / 검색 15% │ │ → rate limit(30r/s)에 걸리지 않게 요청 간격 조절 │ │ │ │ 시나리오 3: Frontend SSR (3 VU, 1분) │ │ → /, /blog, /community 페이지 SSR 응답 시간 │ └──────────────────────────────────────────────────────────┘
rate limit을 고려한 이유가 있습니다. 처음에 최대 50 VU로 풀스택 테스트를 돌렸더니 에러율이 47%가 나왔습니다. 서버 문제가 아니라 Nginx rate limit(IP당 30r/s)에 걸린 거였습니다. k6는 한 대의 머신에서 모든 요청을 보내니까 동일 IP로 초당 30건을 넘기면 전부 429가 됩니다. 그래서 rate limit 안에서 순수 서버 성능만 볼 수 있게 요청 간격을 조절한 별도 스크립트를 만들었습니다.
스레드 풀 튜닝 전후 비교
┌────────────────┬──────────────────┬──────────────────┬───────────┐ │ 메트릭 │ Before │ After │ 변화 │ │ │ (Tomcat 100, │ (Tomcat 30, │ │ │ │ Pool 15) │ Pool 25) │ │ ├────────────────┼──────────────────┼──────────────────┼───────────┤ │ API 평균 │ 55.3ms │ 43.8ms │ -21% │ │ API P50 │ 43.9ms │ 25.3ms │ -42% │ │ API P95 │ 103.9ms │ 104.5ms │ 유사 │ │ API 최대 │ 510.1ms │ 264.5ms │ -48% │ │ Frontend P95 │ 101.2ms │ 106.4ms │ 유사 │ │ 에러율 (5xx) │ 0.00% │ 0.00% │ 동일 │ │ 느린 요청(>1s) │ 0건 │ 0건 │ 동일 │ │ 종합 │ PASS │ PASS │ │ └────────────────┴──────────────────┴──────────────────┴───────────┘
P95는 큰 차이 없지만, 평균과 P50이 눈에 띄게 줄었습니다. 커넥션 풀을 15에서 25로 늘리니 스레드가 커넥션을 기다리는 시간이 줄어든 겁니다. 제일 의미 있는 건 최대 응답시간이 510ms에서 265ms로 절반 가까이 줄었다는 점입니다. tail latency가 줄었다는 건 운 나쁜 요청이 덜 느려졌다는 뜻이니까요.
P95가 변하지 않은 건, 이미 100ms대로 충분히 빠르기 때문입니다. 병목이 커넥션 경합이 아니라 네트워크 RTT와 쿼리 자체 시간이니까, 커넥션 풀을 늘려도 이 구간은 개선되지 않습니다.
Next.js와 PM2: Docker 환경에서 안 쓰는 이유
Next.js를 프로덕션에 올릴 때 PM2를 쓰라는 글이 많습니다. PM2가 해결하는 문제는 세 가지입니다.
PM2가 하는 일: 1. 크래시 자동 재시작 ─── Node.js가 uncaught exception으로 죽으면 살려줌 2. 클러스터 모드 ──────── 싱글 스레드인 Node.js를 CPU 코어 수만큼 띄워줌 3. 무중단 재배포 ──────── 프로세스를 하나씩 교체해서 다운타임 없이 배포
이 중 우리 환경에서 이미 해결된 게 뭔지 따져봤습니다.
┌──────────────────────┬──────────────────────────────┬────────┐ │ PM2가 하는 일 │ 우리 환경에서 누가 하는지 │ 필요? │ ├──────────────────────┼──────────────────────────────┼────────┤ │ 크래시 자동 재시작 │ Docker restart: always │ 불필요 │ │ 메모리 초과 시 재시작 │ Docker memory limits │ 불필요 │ │ 로그 관리 │ Docker json-file 드라이버 │ 불필요 │ │ 클러스터 (멀티코어) │ 해당 없음 │ 검토 │ │ 무중단 재배포 │ Docker up -d (수 초 중단) │ 부분 │ └──────────────────────┴──────────────────────────────┴────────┘
크래시 복구와 로그는 Docker가 대신하고 있으니 PM2를 추가해도 중복입니다. 남는 건 클러스터 모드인데, 이것도 우리 상황에선 의미가 없습니다.
PM2 클러스터를 쓰면 Node.js 프로세스를 CPU 코어 수만큼 띄울 수 있습니다. 4코어 서버라면 Next.js가 4개 떠서 SSR 요청을 분산 처리하죠. 그런데 우리 VM은 2 vCPU이고, 이미 5개 컨테이너(Nginx, Backend, Frontend, MySQL, Image Service)가 CPU를 나눠 쓰고 있습니다. 여기서 Next.js를 2개로 늘리면 메모리가 1.5GB에서 3GB로 뛰고, CPU 경합도 심해집니다.
그리고 k6 테스트에서 Frontend SSR P95가 106ms입니다. SSR이 병목이 아닌데 클러스터를 추가하는 건 과잉이죠.
현재 Frontend는 Next.js standalone 빌드를 node server.js로 직접 실행합니다. PM2 레이어 없이 Docker가 프로세스 관리를 맡는 구조가 이 규모에서는 가장 깔끔합니다.
# frontend/Dockerfile FROM node:20-alpine AS runner COPY /app/.next/standalone ./ COPY /app/.next/static ./.next/static COPY /app/public ./public CMD ["node", "server.js"] # PM2 없이 직접 실행
PM2가 진짜 필요한 건 Docker 없이 직접 Node.js를 돌리는 환경이거나, 4코어 이상 서버에서 Frontend가 CPU 병목인 경우입니다.
서버리스 vs VM
이번에 느낀 건 당연한 건데, 서버리스가 항상 정답은 아니라는 겁니다.
서버리스가 유리한 경우: - 트래픽이 불규칙하고 급증/급감이 심한 서비스 - 운영 인력이 없어 인프라 관리를 맡기고 싶을 때 - 스케일 아웃이 중요한 대규모 서비스 VM이 유리한 경우: - 트래픽이 일정하고 예측 가능한 서비스 ← 우리 - 24시간 돌아가야 하는 DB가 있는 경우 ← 우리 - 비용 예측과 통제가 중요한 경우 ← 우리 - 세밀한 서버 튜닝이 필요한 경우 ← 우리
네 항목 다 "우리"가 붙어 있으니 진작 옮길 걸 싶기도 합니다.
잃은 것과 얻은 것
서버리스를 떠나면서 잃은 것도 있습니다.
┌────────────────────┬────────────────────────────────────┐ │ 잃은 것 │ 얻은 것 │ ├────────────────────┼────────────────────────────────────┤ │ 자동 스케일링 │ 월 비용 55~65% 절감 │ │ 무중단 배포 │ MySQL/JVM/Nginx 상세 튜닝 가능 │ │ 인프라 무관리 │ 로그 직접 접근 (tail -f 가능!) │ │ 관리형 DB 백업 │ Docker 전체를 한 눈에 관리 │ │ │ SSH 접속으로 즉시 디버깅 │ └────────────────────┴────────────────────────────────────┘
자동 스케일링은 어차피 필요 없으니 잃은 게 아닙니다. 무중단 배포는 좀 아쉽지만 10~20초 중단을 새벽에 하면 되고요. 관리형 DB 백업은 cron + mysqldump로 대체했습니다.
반면 얻은 것들은 매일 체감됩니다. docker logs -f ff-backend 한 줄이면 실시간 로그를 볼 수 있고, MySQL slow query log도 바로 확인할 수 있습니다. Cloud Run에서는 Cloud Logging 콘솔을 뒤져야 했는데, 그것도 비용이었고요.
마무리
마이그레이션 결과 ┌─────────────────────────────────────────────────────┐ │ 월 비용: 23~34만원 → ~12만원 (약정 후) │ │ 레이턴시: 변화 없음 (서울→서울) │ │ API P95: 103.9ms → 104.5ms (유지) │ │ API 평균: 55.3ms → 43.8ms (-21%, 스레드 풀 튜닝 후) │ │ 에러율: 0.00% (5xx 기준) │ │ 배포: Cloud Run → SSH + Docker │ │ DB 비용: 10~15만원 → 0원 │ │ LB 비용: 5~8만원 → 0원 │ │ 작업 기간: 약 2일 │ └─────────────────────────────────────────────────────┘
100명 미만 트래픽에 Cloud Run 3개 + Cloud SQL + 로드밸런서를 쓰고 있었으니, 돌이켜 보면 오버엔지니어링이 맞았습니다. VM 한 대로 합치니 비용은 60% 줄었고, 스레드 풀 튜닝까지 하니 오히려 응답 속도도 빨라졌습니다. 서버를 직접 들여다볼 수 있게 된 것도 큽니다.
다음은 GCS를 Cloudflare R2로 옮겨서 egress 비용을 없애는 걸 검토 중이고, VM이 한 달 넘게 안정적으로 돌면 1년 약정을 걸어서 추가 30% 할인을 받을 생각입니다.
서버리스에서 VM으로 돌아가는 게 시대 역행 같기도 한데, 우리 규모에서는 이게 맞는 선택이었습니다.




댓글
댓글을 작성하려면 이 필요합니다.